High Framerate Perception


In my previous post, I covered the design of the Atheon vision engine. In this post, I will talk about how Atheon and Mobius layer a portfolio of optimizations throughout various systems and sub-systems to achieve speeds between 100x and 500x faster than my legacy implementations.
Before I can begin, I need to give some background on Mobius. Mobius is a Lua-based automation system, and is both the core product provided by the Chronos platform and the main consumer of the Atheon vision library.
Note: neither Chronos nor Mobius are products for sale, but talking about software in this way is an occupational hazard.
Achieving high performance was a key goal of Atheon and a driving factor behind the caching-first, duplication-phobic design described in the Atheon post. Taken alone, the design boasted performance of up to 25x that of its predecessor.
Operating a few levels up from the generic, atomic-scale optimization details of Atheon, Mobius can leverage its much richer context to squeeze out additional gains. As a result, Mobius achieves a framerate between 4x and 20x higher.
1. Reaction Time: a processing framerate of
200fps needs only 5 milliseconds to understand and react to a new frame. If processing framerate was the same as input framerate at 20fps, there would be 50 milliseconds of total reaction latency.2. Resource Consumption: multiple Mobius instances can run in parallel, and these instances will contend for resources. As processing framerate increases, resource usage and contention decreases. If processing framerate is 10x higher than input framerate, Mobius can run roughly 10 instances before experiencing performance degradation.
Prefetching
In my post about Atheon, I touched on the concept of thread-agnosticism. In a nutshell: vision operations are implemented such that they can be parallelized or not, and they neither know nor care which one is happening.
IExecutor in order to schedule work. When an IExecutor performs any scheduled work, it passes another IExecutor along for that work to use. When a ThreadedExecutor is parallelizing work, it will pass along an InlineExecutor which runs any scheduled work in-place at the time of scheduling.This means Mobius can execute vision operations in two different manners:
Pipeline Parallelization
In this case, the thread pool (a ThreadedExecutor) is used to run multiple pipelines at the same time, providing each an InlineExecutor. The internal work—pixel matching, image classification, etc—for each pipeline is executed inline, since the thread pool is in use at a shallower level. In code:
void LuaBridge::runPrefetch() {
for (auto& p : this->prefetch) {
this->executor->execute([&, this](IExecutor* e) {
this->frame->runPipeline(e, p);
});
}
this->executor->join();
}Snippet 1 - an executor is used to prefetch and frame->runPipeline is given a new IExecutor e
Perceptor Parallelization
In this case, a single pipeline is run on its own and is provided a ThreadedExecutor. As vision operations happen, their internal work can be scheduled in the thread pool. Moreover, if a pipeline contains nested pipelines—for image slicing, character classification, etc—pipeline parallelization will be available at this deeper level. In code:
int LuaEnv::executeCognitionPipeline()
{
auto args = this->getArgs<CognitionPipeline>();
if (!args.has_value()) return this->luaRet(false, "invalid args");
auto pipeline = std::get<0>(*args);
auto result = this->frame->runPipeline(
this->executor.get(),
*pipeline
);
return this->luaRetPerception(result);
}
Snippet 2 - executor is given directly to frame->runPipeline
When it comes time for Mobius to evaluate a new frame, it must decide between these two forms of parallelization: find a bunch of stuff at once, or find one thing at a time.
Pipeline parallelization is generally faster: in addition to doing multiple things at once, it allows the thread pool to attack larger chunks of work at a time. In niche cases, however, perceptor parallelization can be faster. Moreover, the automation engine doesn't always care about the entirety of a frame: sometimes, only a small subset of loaded pipelines is run against a frame.
Prefetching is a way to take advantage of both forms of parallelization. As it runs, Mobius collects profiling data about how the automation code uses the vision engine. As the automation engine exhibits different workloads, Mobius uses the profiling information to sort pipelines into two buckets: prefetch and on-demand.
When a frame first arrives, pipeline parallelization is used to execute all prefetch pipelines as shown in Snippet 1. Once prefetch is complete, the automation code runs and starts evaluating pipelines. When it evaluates a pipeline, it ends up in the code from Snippet 2. If pipeline ran during prefetch, a quick chain of lookups occur in the perception tree to return the existing result. If pipeline was not in the prefetch set, on the other hand, perceptor parallelization is used to newly run the pipeline against the frame and return the result.
Performance
The effect of prefetching depends on the size of the thread pool, the nature of the script that is being run, and how Mobius decides to bucket pipelines. Keeping that in mind, let's look at an example.
See Image 1. In the top left, it shows that 47 of 71 total pipelines are in the prefetch bucket.
Note: the number 71 comes from the number of unique cognitions loaded, as those represent pipelines which run directly against the input frame. The 121 unique pipelines shown includes those which are nested within other pipelines and cannot be directly prefetched.
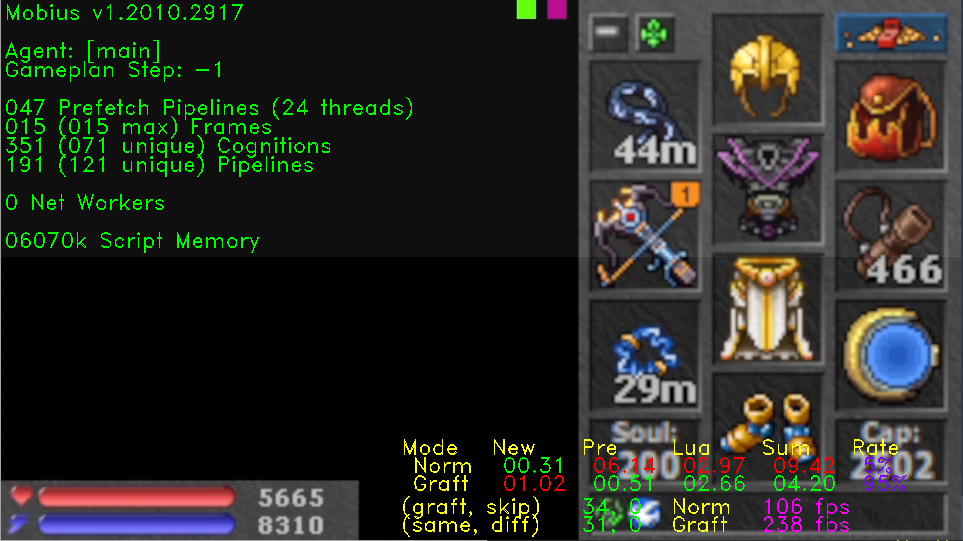
What is the takeaway? In this case, Mobius decided to use pipeline parallelization to execute 47 pipelines across 24 threads averaging 6.14 milliseconds per frame. These pipelines represented about 66% of loaded pipelines, but were all much more likely to be relevant compared to the remaining 34%.
Now take a look at Image 2. This shows the same exact scenario, but prefetch is being skipped entirely because the thread pool is disabled. Here, the processing framerate is 43fps compared to 106fps with prefetch.
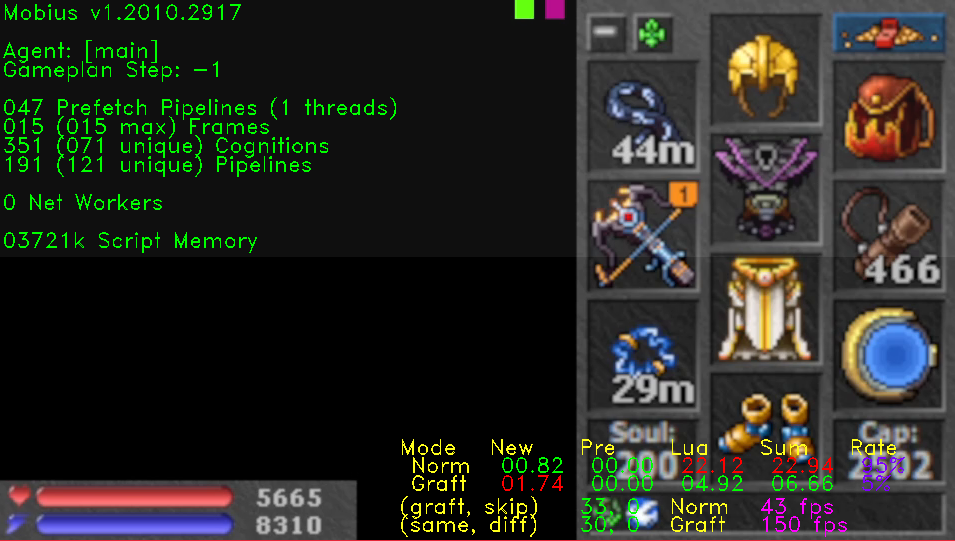
This scenario shows a 2.46x framerate gain in favor of prefetch, and I've seen gains of 10x under specific conditions.
Grafting
My post on Atheon makes clear one fundamental idea: perception is a tree. As it executes vision pipelines against a frame, the operations are memoized in a tree where the edges are operations and the nodes are the perceptions they produced.
Mobius takes advantage of this structural markup, utilizing it to graft branches from the perception tree of one frame to the next. When a new frame arrives, Mobius walks the perception tree of the previous frame. The region corresponding to each node is recorded, the region list is de-duplicated, and the thread pool is used to parallelize the matching of pixels in the new and previous frame. When a region is unchanged in both images, the corresponding branch is grafted onto the new frame.
These direct pixel matches are at least as fast as any vision operation they're attempting to short circuit, and they are often faster as they can cop-out as soon as a pixel doesn't match. Moreover, profiling information can be used to decide on pixel matching strategies, such as top-down, ends-in, or middle-out, with the goal of checking pixels in an order which yields a mismatch with the fewest comparisons possible.
Performance
The performance of grafting, in particular, is heavily subject to the workload and context. In cases where every frame has new information in every region of interest, it can actually slow frames down by a few milliseconds. When less is going on, however, it can more than double the processing framerate.
Here is an example. In Clip 1, areas are highlighted in green if they were unchanged and red otherwise. On the left, numbers corresponding to these areas are shown as (same, diff), and the numbers of corresponding branches shown as (graft, skip). Nearby, magenta text shows the processing framerate (1000.0 / totalFrameTime followed by fps) for the normal and grafted frames.
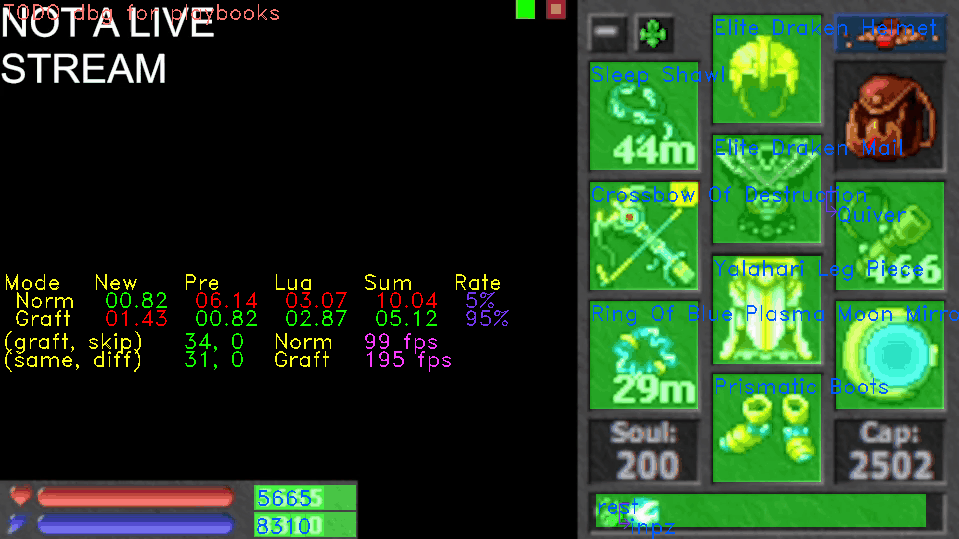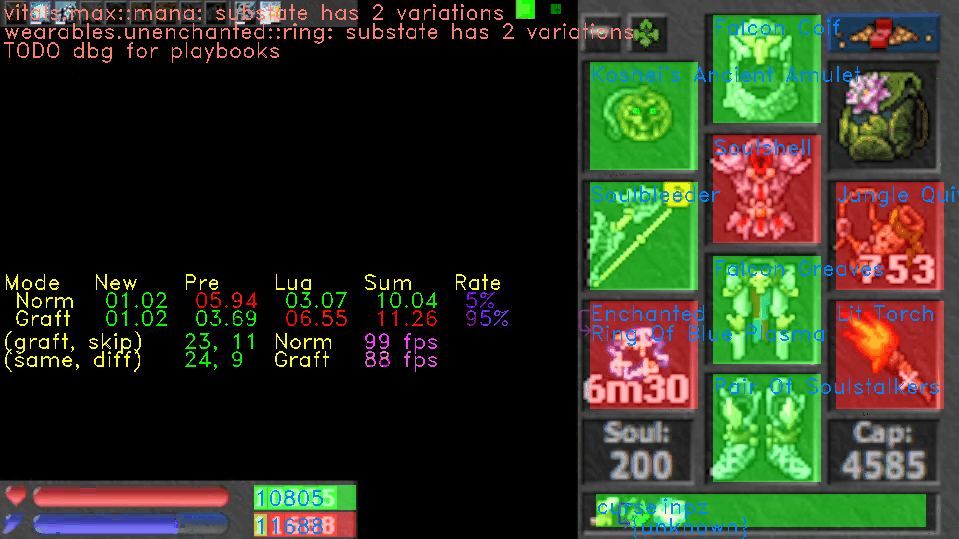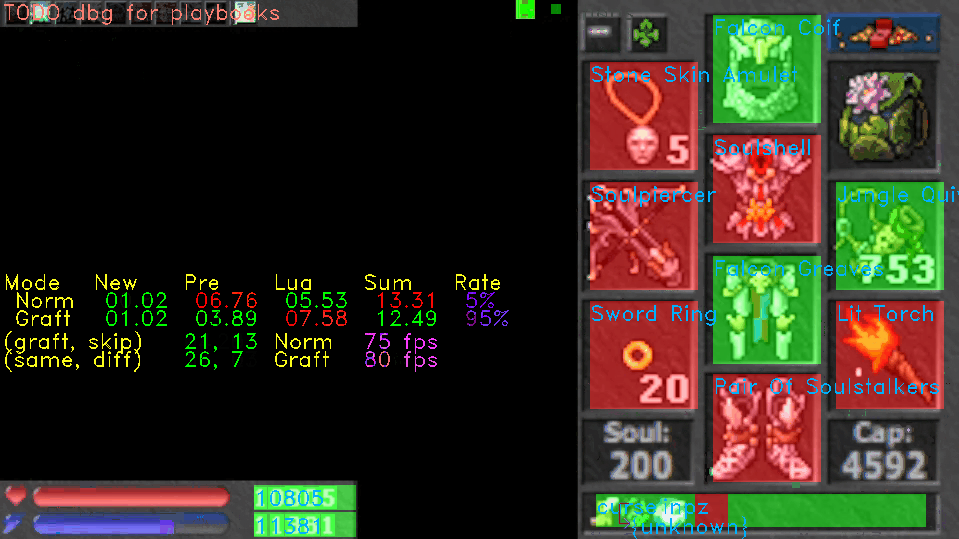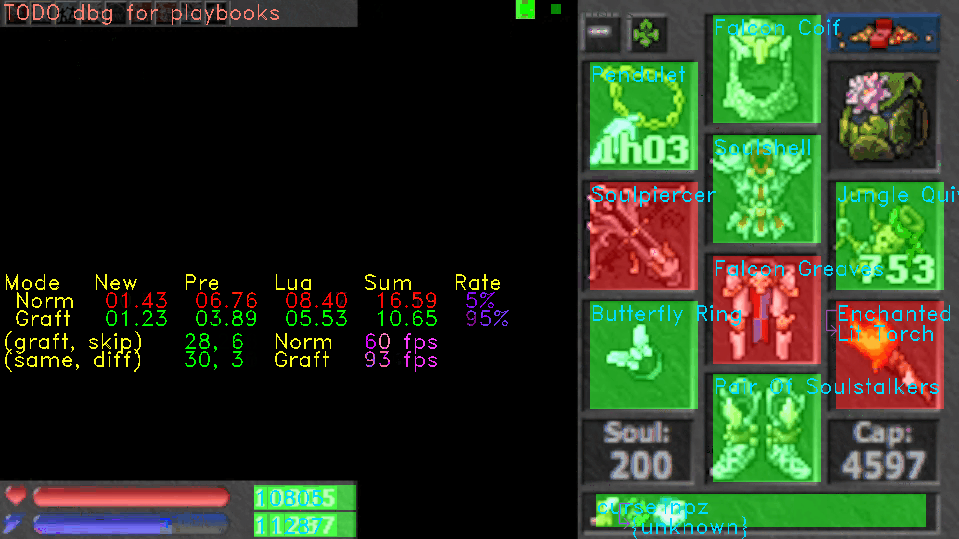
When Clip 1 starts, the bot is receiving a static frame. There are some changes due to encoding keyframes and artifacts, but most frames are entirely grafted. At times, the average framerate is almost double, soaring to 190fps compared to 99fps.
As Clip 1 progresses, Mobius begins to receive a live frame with animated equipment and varying health and mana values. Here, the framerate nearly levels to a point of break-even. Some frames probably cost more due to grafting, but there is still a slight advantage of 85fps compared to 75fps on average.
For another vantage point, look again at Image 1 and Image 2 which demonstrate performance on a mostly unchanging frame. These show grafted frames without prefetch only taking 6.66 / 4.20 = 1.59 times longer than those with prefetch, compared to 2.46x longer when neither prefetch nor grafting is used.
I swear I did not contrive the numbers above.
In this very-grafting-friendly scenario, grafted frames without prefetch beat prefetched frames without grafting at 150fps to 106fps. Moreover, grafting provided a 3.49x speedup when prefetch was disabled. There is some nuance worth noting: when prefetch is disabled, grafting is also unable to use the thread pool, which slows it down somewhat.
Memory Usage
Grafting has another advantage worth noting: memory savings. Mobius will generally keep a buffer of historical frames for various purposes. Grafting a branch from one frame to another costs one simple std::map node, but represents a deeply-nested tree of lightweight semantic information and heavyweight pixel data. The lazier parts of a frame might be grafted for 30 or more frames in a row. When 15 or 20 of those frames are retained in the historical buffer, those savings can add up.
Synergistic Consensus
While there are more specific cases, Mobius generally uses the historical frame buffer to build consensus across frames. In automation code, consensus allows a developer to trade reaction time for accuracy on a pipeline-by-pipeline basis. This comes in handy because recognizing some states can be really hard during transition (mainly due to encoding artifacts), but made easy by requiring a consistent output from N frames before recognizing a state. N is decided by the script and further depends on the input framerate. The size of the historical buffer depends on the highest N requested for consensus.
In Clip 1, this system appears in the form of messages, top left, with this format: {state name}::{substate name}: substate has {number} variations. These messages are rendered by the automation engine to convey that an automation state called {state name} has not reached consensus because there are {number} (> 1) different unique values reached when querying current and historical frames for the pipeline referenced by {substate name}.
With that explained, an additional synergistic benefit between grafting and consensus becomes clear. When checking for consensus, the automation engine queries a pipeline against multiple frames, serializes the resulting Perception into a Lua object, and deduplicates the Lua objects based on a deep comparison. When grafting occurs, multiple historical frames may have the same instance of a Perception in their perception tree. In that case, the pointer given to Lua will remain the same across frames, allowing an exact equality check to short circuit consensus' state comparison before it performs any expensive work.
Profile Guided Grafting
Even with the same bot instance doing the same work on the same game, something as simple as whether or not the contents are animated has a large effect on performance. For this reason, Mobius profiles the timing of the different approaches and prefers to take the faster approach. In Clip 1, there is a purple percentage rate shown for each strategy; these numbers correspond to the percentage of frames to which the strategy is applied.
When grafting provides large advantage, it runs on 95% of frames. When the advantage lessens, it drops to 90%, 70%, and even 50% of frames. Here's a very-likely-to-be-improved look at how that works:
void LuaBridge::balanceGraftProbability()
{
auto graftAvg =
this->frameTimer.average("update_grafted") +
this->frameTimer.average("prefetch_grafted");
auto nograftAvg =
this->frameTimer.average("update") +
this->frameTimer.average("prefetch");
this->graftProbability = 50; // default behavior is 50/50 split
if (graftAvg * 1.5f <= nograftAvg)
this->graftProbability = 95; // graft 50% faster, 95% prob
else if (graftAvg * 1.3f <= nograftAvg)
this->graftProbability = 90; // graft 30% faster, 90% prob
else if (graftAvg * 1.15f <= nograftAvg)
this->graftProbability = 75; // graft 15% faster, 75% prob
else if (nograftAvg * 1.5f <= graftAvg)
this->graftProbability = 5; // nograft 50% faster, 95% prob
else if (nograftAvg * 1.3f <= graftAvg)
this->graftProbability = 10; // nograft 30% faster, 90% prob
else if (nograftAvg * 1.15f <= graftAvg)
this->graftProbability = 25; // nograft 15% faster, 75% prob
}
One detail of key importance: the balancing is probabilistic, and at no time will any strategy have a probability of 0%. This ensures that the profiling data doesn't go stale as the workload evolves. Typically, Mobius will run with an input framerate of 20fps and this->frameTimer will keep a rolling average of the last 20 events. When either strategy is at 5% probability, it can be expected to run once per second: 5% = 5/100 = 1/20, 20fps * 1/20 = 1fps. This means, at worst, this->frameTimer will take 20 seconds to fully adapt to a new workload. But it can also take 10 seconds (10% probability), 4 seconds (25% probability), or 2 seconds (50% probability).
Grafting is Prefetching
As I was wrapping up the first draft of this post, my dog very sweetly demanded I join him for a walk. During this walk, I had a realization: grafting is just an alternate form of prefetching. With that newfound insight, I understood that additional speed could be gained by not prefetching when grafting is successful.
To put this theory to the test, I updated the grafting code to record which pipelines are successfully grafted. I updated the prefetch code to deduplicate the prefetch set against the grafted set, and only prefetch if the remaining work meets some arbitrary thresholds:
void LuaBridge::runPrefetch() {
std::vector<Atheon::CognitionPipeline> tofetch;
tofetch.reserve(prefetch.size());
for (auto& p : prefetch) {
if (!p.size()) continue;
if (graftedCognitions.find(p[0]) != graftedCognitions.end()) continue;
tofetch.push_back(p);
}
if (tofetch.size() <= prefetch.size() / 3) return;
if (tofetch.size() <= executor->getWorkerCount() / 3) return;
for (auto& p : tofetch) {
executor->execute([&, this](Atheon::IExecutor* e) {
haystack->runPipeline(e, p);
});
}
executor->join();
}The results were better than I imagined. The detailed timings are hard to measure, as the method creates an interdependency between graft and prefetch timings, biases prefetching time downwards, and blames any additional cost on the Lua execution time.
Nonetheless, the cumulative results are clear. Running the same graft-friendly case from earlier, the average jumped from 180fps to 305fps with peaks going from 200fps to an astounding 605fps. It is so fast that it sometimes falls within the error margin of the high resolution timer, appears to run in negative time, and shows peaks in the -2,147,483,648fps ballpark.
Even on the same graft-hostile case from earlier, the effect is still seen. The average soars from 85fps to roughly 203fps, with peaks leaping from 105fps to 305fps.
Understanding this is actually pretty simple. When grafted branches significantly overlap with prefetch pipelines, almost the entirety of prefetch will be spent chasing pointers, reference counting, querying the cache, and determining there is no work to do. Binary search is fast, and still more time would be spent on it than computer vision. There may be some advantage left to gain, but it is dwarfed by the overhead and wasted cycles.
When grafting doesn't find many unchanged regions, it spends a lot less time running due to the pixel comparisons short circuiting on the first mismatch, often after looking at only a minority of the pixels. In this case, there is a lot of work left for prefetch to do, and it will pay for the time-cost of grafting multiple times over.
Future Work
This post is getting way too long. See Appendix: Higher Framerate Perception if you care about upcoming work, experiments, and theories relating to performance.
Conclusion
It should be clear by now that the bolded numbers in the introduction are cherry-picked bullshit, as is to be expected. Regardless, there are still large and clear performance gains. They are situational, inconsistent, usually ephemeral, and hard to quantify, but when combined provide a nominal speedup of roughly ~5x over vanilla usage of Atheon.
The increase in speed is owed primarily to the techniques detailed in this post, but some small amount is due to good design decisions and optimizations cascading into various sub-systems. This was demonstrated quite nicely by examining the side effects of grafting on consensus and prefetching.