Let There be Sight

In this post, I'm going to explain the design behind the computer vision engine that Chronos uses. That engine–named Atheon–is tailored to perform computer vision tasks against computer generated interfaces. Working in such a narrow domain enables powerful optimizations and designs which wouldn't make as much sense for computer vision against real-world images, and I find that niche to be quite an interesting one.
Let's jump in, and figure out how this thing actually sees:
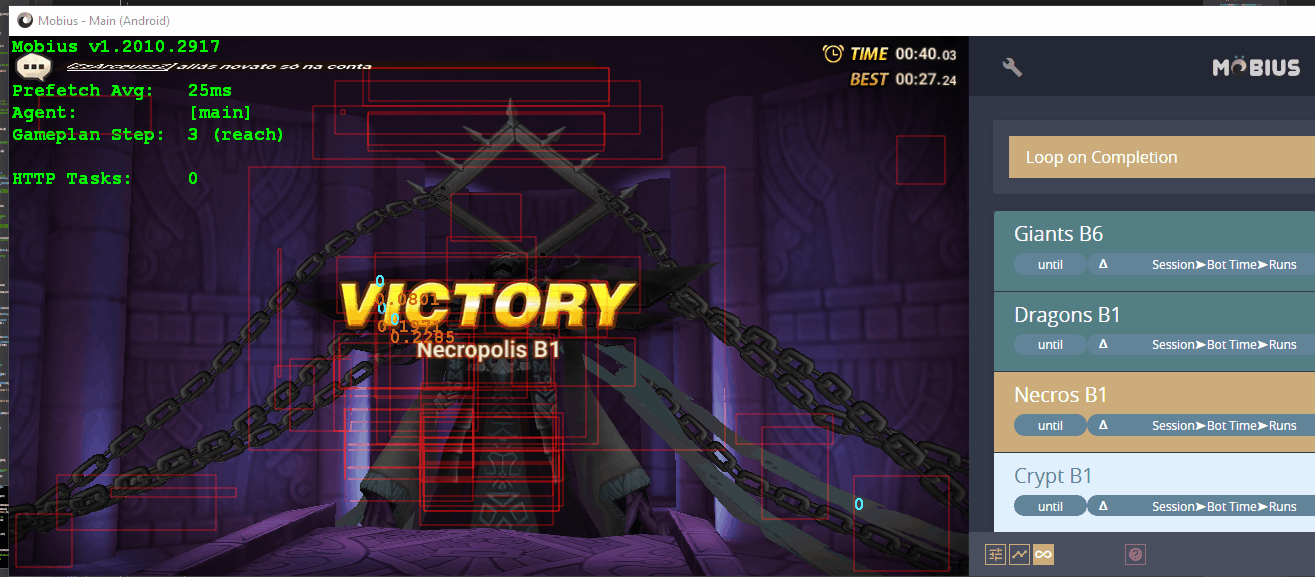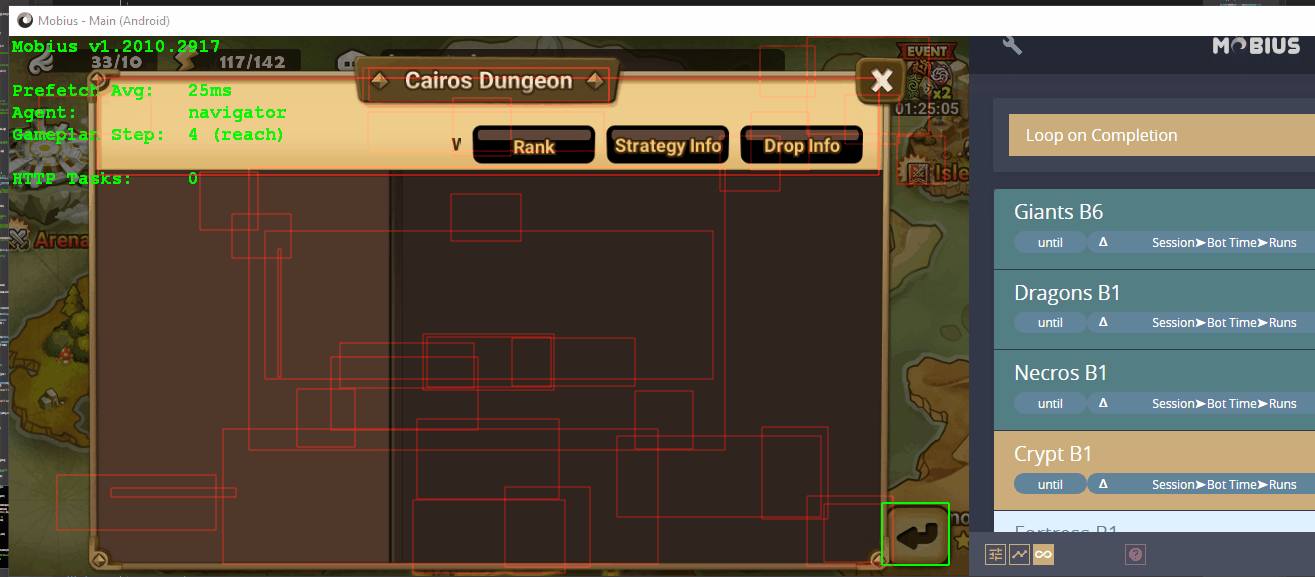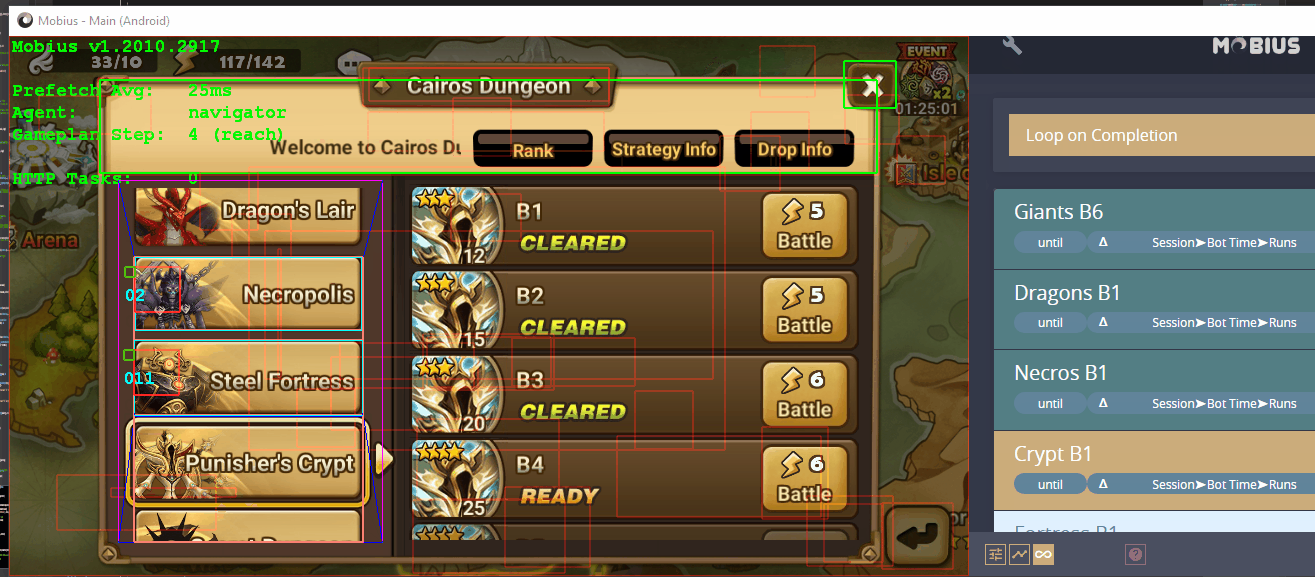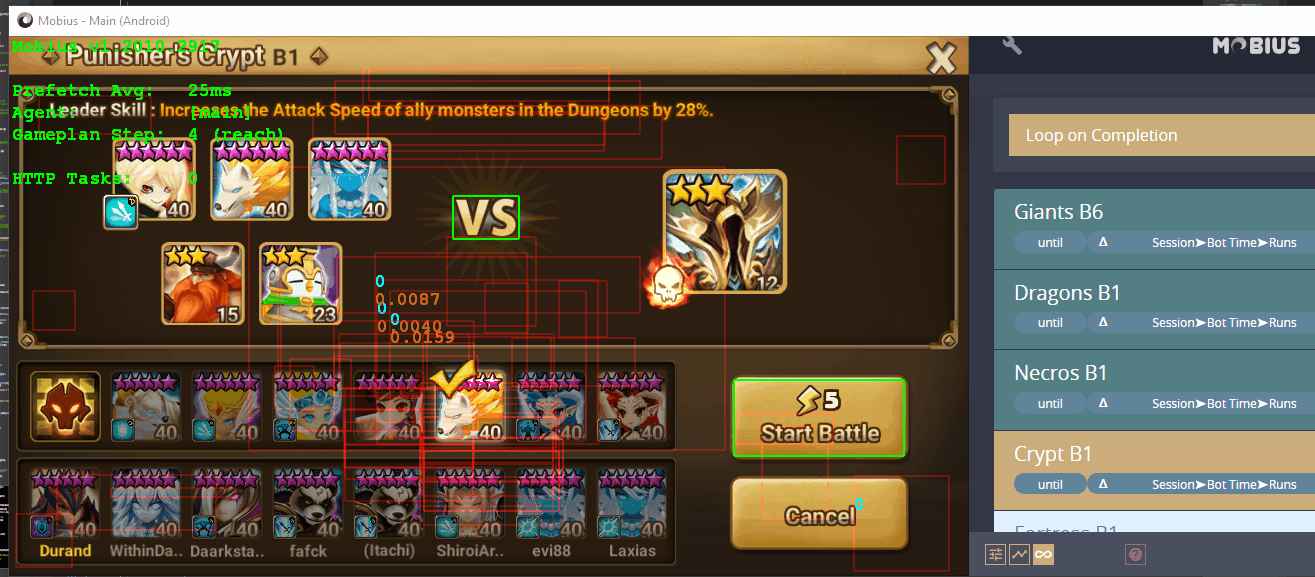
Perception is a Tree
Atheon is built around an important component: the Perception. At the core, a Perception is simply a std::variant which may represent pixels (cv::Mat), vectors (vector<float>), a number (int or double), a boolean, a string, or rectangles (vector<cv::Rect>). The variant may also contain a list of variants, called a multi-perception.
Aside from the variant and some metadata, each Perception also contains a PerceptionCache. You can think of this cache as a list of key-value pairs, where each value is a Perception and each key is something called a Cognition. But what is a Cognition?
Atomic Cognition
Each Cognition can be thought of as an atomic operation, where atomic is used in the classical sense to mean smallest possible.

A Cognition executes by taking a Perception A on the left and returning a new Perception B on the right. When B is returned, a shared pointer to it is added to A's PerceptionCache with a weak pointer to the Cognition as a key. If the same Cognition were to execute against A again, the computation would be skipped and B would be returned. Here are some example Cognition implementations:
Cropexpects pixels on the left and returns a cropped subset of those pixels on the right.Thresholdexpects pixels on the left and returns pixels of the same size with a single channel (black and white) on the right. The color of each returned pixel depends on whether or not the corresponding source pixel is above some threshold value.Contoursexpects black and white pixels on the left and returns rectangles on the right. The rectangles are the result of running edge detection on the input image and finding the bounding rectangles of all adjacent edges.Vectorizeexpects pixels on the left and outputs vectors on the right. The length of the vectors matches the length of the input (w * h * channels) and the pixel data is simply transformed frombytes between0and255tofloats between0and1. In some cases, input pixels may be scaled or padded to fit some predefined size.ConvNetexpects vectors on the left and outputs vectors on the right. The output is a list of probabilities, where each index corresponds to some class.ClassifyVectorsexpects vectors on the left and outputs an integer on the right. The integer is simply the index of the highest value in the vector, which effectively turns a list of probabilities into a concrete classification.ExtractTextexpects a multi-perception of integers on the left and returns a string on the right. Each integer is used to index a list of characters from a character set, and the characters are concatenated into a result. There are also tunable heuristics for inserting spaces and newlines based on the position of each character.
Typically, Cognitions are specified as a list and executed in sequence using what is called a CognitionPipeline. Execution of these pipelines and caching of the results yields a tree of Perceptions: the root is the initial input, the edges represent operations, and the nodes are the results. Here is an example of a single branch:

The pipeline that created this branch corresponds to the first three operations listed above: Crop -> Threshold -> Contours. Here is the flow:
- A 960x540 frame is received.
- A crop operation is run on it, and an image of some text is returned.
- A threshold operation is then preformed, yielding a mask of the characters.
- From there, a contour detection operation is executed and returns the absolute bounding rectangles of the individual characters.
With three simple operations, an Optical Character Recognition (OCR) task was initiated. Now let's look at another branch in the same tree, showing how the OCR task is completed using a Vectorize -> ConvNet -> ClassifyVectors -> ExtractText pipeline:
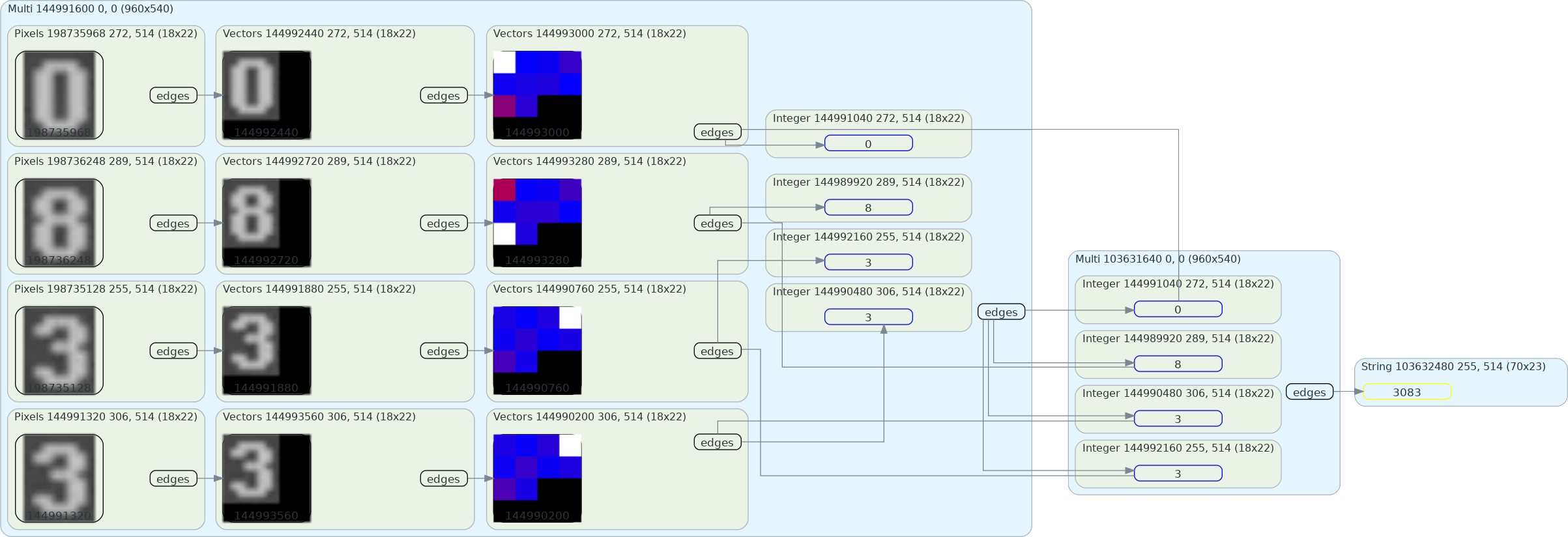
With those seven simple Cognitions, Atheon was able to correctly turn pixels into the text 3083. Pretty cool, right?
There is actually one detail missing, and you might have even caught it: how exactly did the rectangles from Figure 1 end up flowing into Figure 2? This is the result of running a Compositor (a specific type of Cognition) against the input frame and the rectangles produced from the branch in Figure 1. Mixing Perceptions in this way is the special task of Compositors.
The Compositor in this case–called Slice–accepts one CognitionPipeline resolving to some pixels and another resolving to some rectangles. It then crops the pixels according to the rectangles–which in this case were produced as shown in Figure 1–and returns a multi-perception of those pixels. This multi-perception is what was fed into the OCR task shown in Figure 2.
There is actually still a final Cognition missing: ForEach. Let's express the entire pipeline in a markup notation:
Crop -> Slice(
{}, // Empty, gives the cropped frame (left is passed along)
Threshold -> Contours
) -> ForEach( // Loops over a multi-perception
Vectorize -> ConvNet -> ClassifyVectors
) -> ExtractTextIf you were following along with the text and Figure 2, you might have noticed that the colorful little grids are actually activations from the output layer of the
ConvNet. In these grids, black means "equal to the minimum value in the vector" and white the same for maximum. In-between the extremes, there is a gradient from blue (small) to red (high).With this additional information, you might notice a lot more. This
ConvNet thinks 8 looks a bit like 3, but even more like 0. It doesn't think that 0 looks as much like 8, but still does a little.In this case, the character set given to
ExtractText is for numbers only, so the number returned from ClassifyVectors corresponds directly to the mapped characters. This means that number 3 is character 3 and so on. Most of the time, the numbers to the right of the output activations won't map cleanly to the output text, as the character set will contain more than integers.As an aside, I love that this sort of visualization just fell out of Atheon's architecture. It wouldn't be possible if vision operations were a mess of ad-hoc spaghetti, but it wasn't the point of the design.
Design Roots
I'm going to dedicate an entire post to Mobius' automation engine, but a quick overview is in order. If the vision engine is "perception in, perception out", then the automation engine is "frames in, actuation out". It marries Atheon's C++ core up to a Lua environment and provides an easy-to-use framework for automating actions based on the results of computer vision.
My initial vision engine, which Atheon replaced, worked differently. The operations were monolithic, each representing an entire task. They took a cv::Mat as input, and produced some object that could be queried for a boolean, a string, or a number. It wasn't a variant; all could return meaningful values, and what they returned was implementation defined.
This worked well for what it was, but it had some core problems. Because the Lua engine is designed for ease-of-use, scripts would often want to preform duplicate operations. Here's an example:
1. Next, an unrelated part of the script runs the same classifier on the same pixels to check if the result class is 7.The duplicated computation was only the start. There was also duplicate resource consumption, such as every ConvNet-equivalent operation loading its own copy of weights and its own buffers for execution. This problem, and others, cascaded into all parts of the system.
It was unreasonable to expect deduplication on the Lua side. It complicated development, was out of alignment with the design of the framework, and just didn't feel right.
To prevent computational duplication, the legacy vision engine had a precursor to the PerceptionCache: a mechanism which cached the result of operations on a per-frame basis. When I decided I wanted to flesh the idea out for Atheon, I realized that it would only really make sense if operations were made atomic. Further, I realized that atomic operations would require a standardized data-flow mechanism, leading to the Cognition, Perception, and PerceptionCache concepts.
The final piece of the puzzle is a factory which deduplicates the instantiation of Cognition instances. When told to create a new Cognition, it creates a std::tuple containing the construction arguments. This tuple is used as a lookup key into an std::map which holds weak pointers to (maybe) existing Cognitions. If lookup fails or the object is gone, it is constructed anew, the cache is updated, and a shared pointer to the new Cognition is returned. Otherwise, a shared pointer to the cached Cognition is returned.
This factory clearly manages to deduplicate resources, but the fact that it also deduplicates computation isn't as obvious. Take a moment and think back to the PerceptionCache; because each key is a pointer to a Cognition, the cached pointers returned from the Cognition factory also deduplicate lookups into a PerceptionCache.
Spatial Awareness
I was implementing the design, and it was perfect... almost. I couldn't get over the fact that the computational deduplication was incomplete. You see, Cognition operations may be conceptually atomic, but that is realistically not the case. An atomic computer vision operation is reading or writing a single pixel, something which obviously cannot be broken down into this type of perception tree.
And, of course, this made sense: the vast majority of operations would benefit from the construction-level deduplication, and the design wouldn't bog-down the processing with endless bookkeeping.
But I was still bothered. Let me explain the edge-case:
0, 0 with a size of 100x100. The output of this operation is a mask (pixels) of size 100x100. Now, an unrelated piece of code runs the same operation with the same parameters at 50, 50 with a size of 100x100.In this case, 25% of the second operation's work will have already been done, since the lower right quadrant of the first operation overlaps with the upper left quadrant of the second.
This wouldn't be deduplicated! With the design so far, if the operation takes the target rectangle as a parameter, the Cognition will be different for each operation. If the target rectangle is instead pre-cropped by another operation, then the crops will be separate Perceptions each with their own PerceptionCache.
But 25% of the work was already done!
That's when I came up with the idea of the SpatialCache. Just as the PerceptionCache deduplicates operations based on the Cognition, the SpatialCache deduplicates them based on spatial overlap.
In the above example, the SpatialCache on the input image will first record the operation at 0, 0 100x100. Then, when it is queried for the operation at 50, 50 100x100, it will find that the target rectangle collides with a past operation of the same kind. It will then fragment the remaining parts of the rectangle into efficiently-sized pieces, dispatch the requested operation on each piece individually (sometimes threaded), update the SpatialCache, and return.
Perception", but you'd be wrong. Instead, the isolated operations write into their own chunk of a shared output buffer so that no copy or aggregation step is required. Later, you'll see a function called Utils::LocklessThread() which works in the same way.This method can be applied to any Cognition where the result is expected to be uniform across the input image. I call this type of Cognition a Mutator. Heavy operations, such as those used for object detection, receive monumental speed improvements from their Mutator status.
What does it mean for a Mutator to have a uniform result? If you recall, Threshold accepts pixels and returns black and white pixels of the same size. Because Threshold does a something like avg(pixels[x][y]) > thresh to determine if the output at x, y should be black or white, the operation is uniform. If you run Threshold on an image as a whole or run it on individual pixels and reassemble the results, both outputs will be the same.
Contours and ConvNet cannot be Mutators, on the other hand, because the results of each operation may change based on the size and position of the inputs. Moreover, even if that wasn't the case, it isn't clear how to merge the fragmented results together.
Public Pool
For all of its faults, the legacy engine was still fast enough. Whenever possible, it would batch operations up and hurl them at lightweight thread pool which could run them simultaneously. In cases where only one operation needed to run, though, it would do so in a single thread as the pool sat idle.
I decided Atheon should be threading-agnostic. I wanted to design it such that a Cognition could run in a thread or not, and not know the difference. I wanted to be able to use the thread pool at the root to parallelize multiple CognitionPipelines. When only one CognitionPipeline is present, I wanted to be able to pass the pool along so the Cognitions could access it. I wanted a Compositor to be able to parallelize the pipelines it has internally and a Mutator to pool the fragmented operations when pulling from cache.
My solution was to create IExecutor. In a nutshell:
class IExecutor
{
public:
typedef std::function<void(IExecutor*)> Action;
virtual int getIndex() const = 0;
virtual void join() = 0;
virtual void execute(Action action) = 0;
};
It is as simple as it looks: a class which lets you schedule some Action to do. You call execute() to schedule the task, then call join() to block until all tasks are done. When a task is invoked, it is passed an IExecutor which it can use to schedule tasks of its own.
There are two implementations to this interface. InlineExecutor will simply execute the work in-place and pass itself as the IExecutor to the task. This is a no-threading scenario, and join() is essentially a NOP.
ThreadedExecutor, on the other hand, will schedule the work in a thread pool. When a task is invoked, it will be given an InlineExecutor so that any work it schedules happens within the same thread.
The result is something that is easy to use and elegant. Here is a Compositor which uses the system to potentially parallelize some work, with no locks used:
ptrs::Perception::Shared Spread::compose(
IExecutor* executor,
const ptrs::Perception::Shared& origin,
const std::vector<ptrs::Perception::Shared>& _
) const
{
std::vector<ptrs::Perception::Shared> results;
auto work = [&](IExecutor* e, const auto& in, auto& out) {
out = origin->runPipeline(e, in);
};
Utils::LocklessThread(executor, this->spreadPipelines, work, results);
return Perception::create(origin->rect(), PerceptionVariant(results));
};Having the parallelism built into the engine like this is massively advantageous. Not only is it blazingly fast, such that it can run realtime at 60 frames per second without breaking ~20% CPU on my 24-core system, but the speed is also adaptable. The automation engine actually does a lot of fancy optimization to put the dynamic threading to efficient use. I'll talk about this in a later post.
cv::Lego
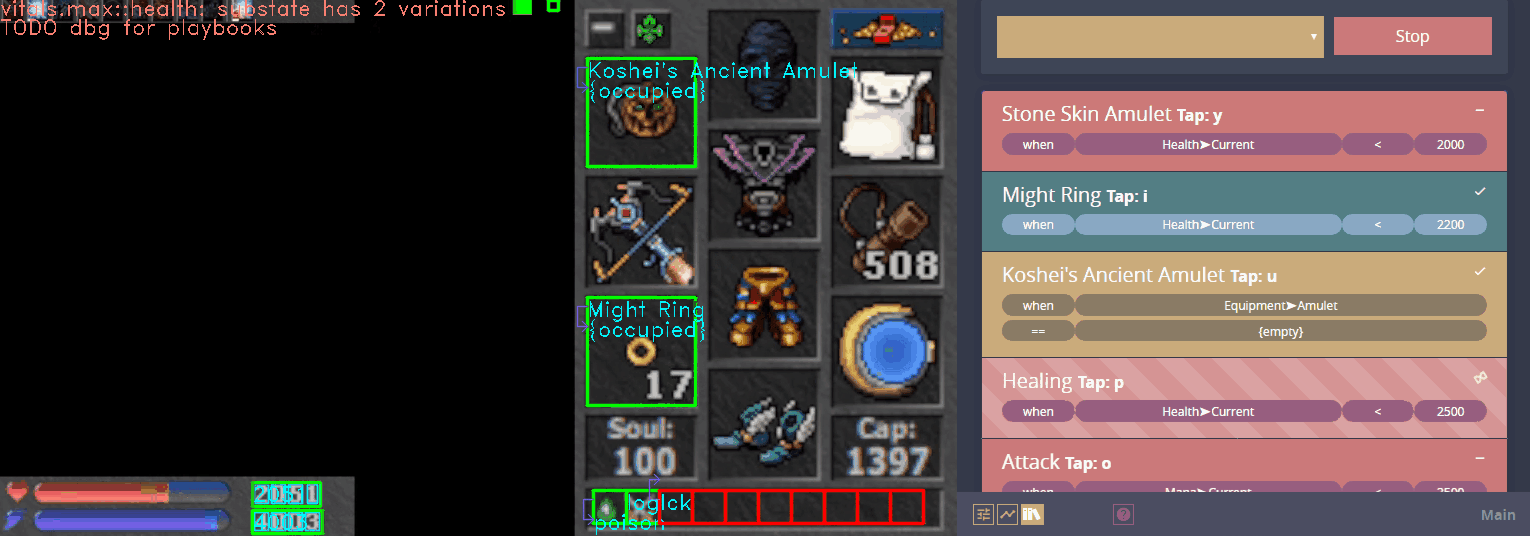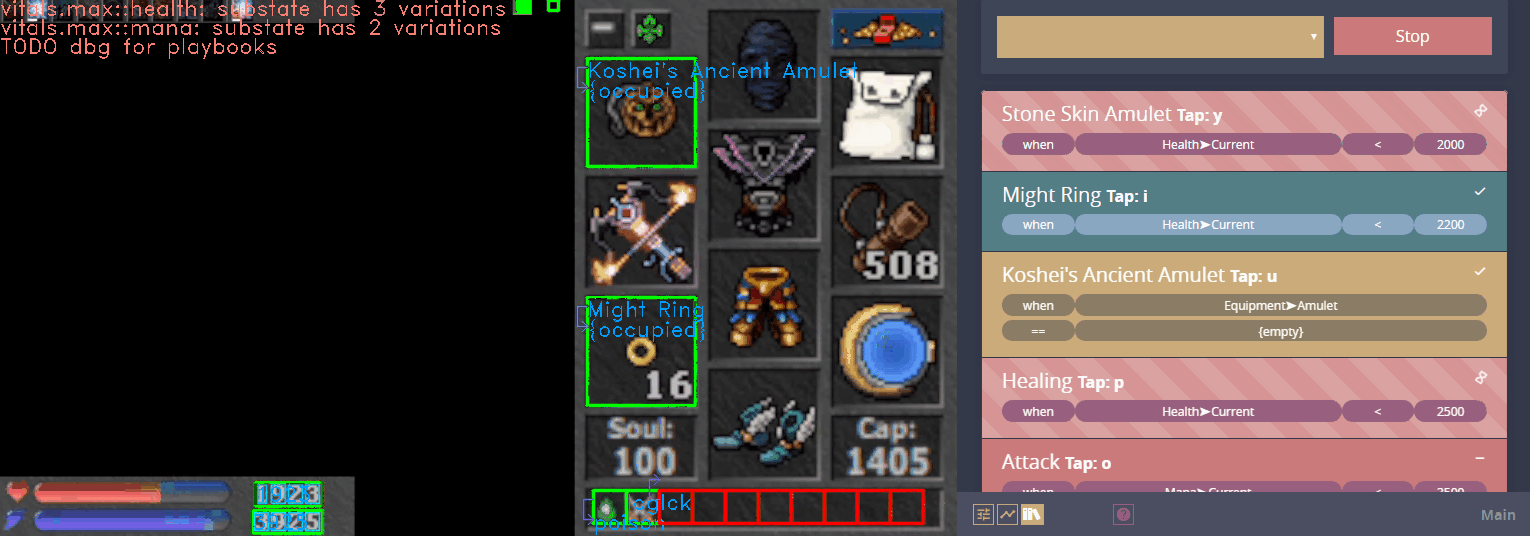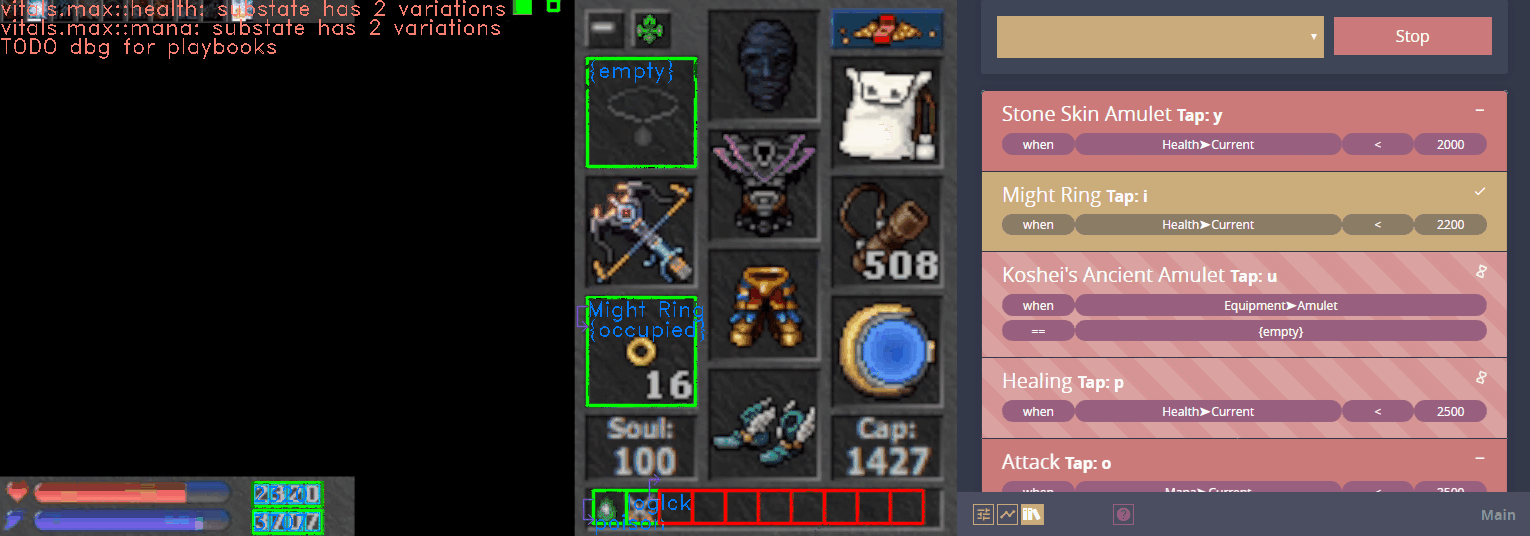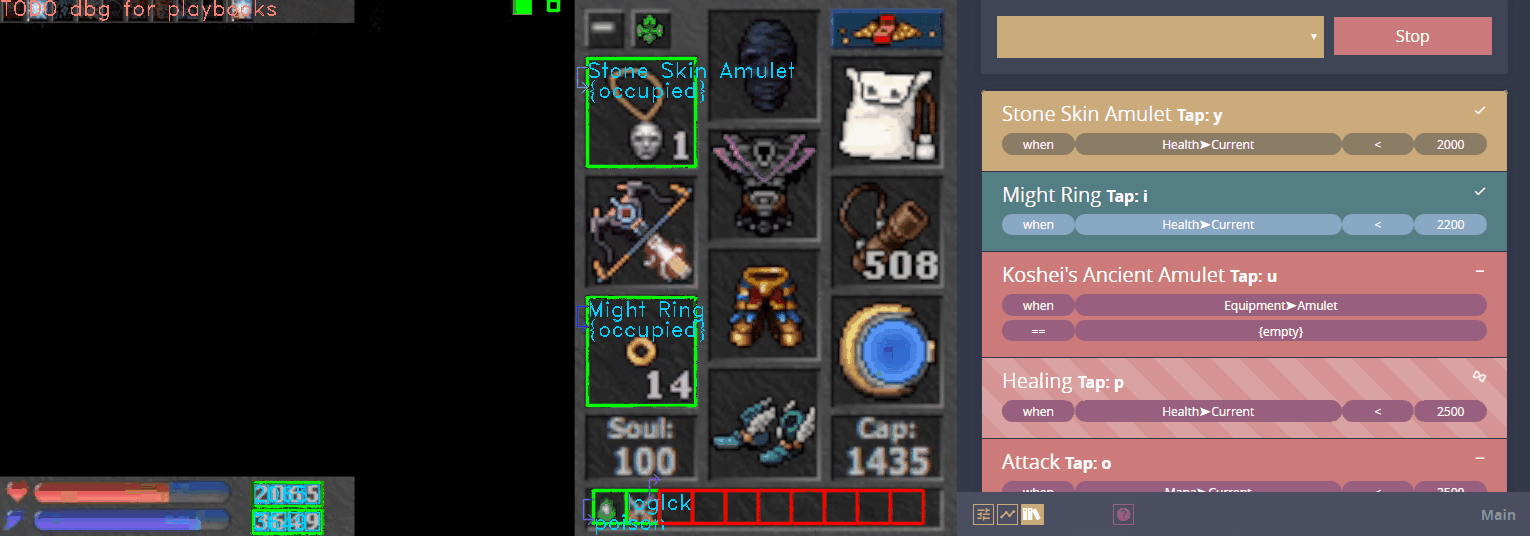
Atheon effectively became computer vision LEGO, where you can build anything out of simple parts. The same basic steps that were used in Figure 1 and 2 are used to identify monster icons in this scrolling list:
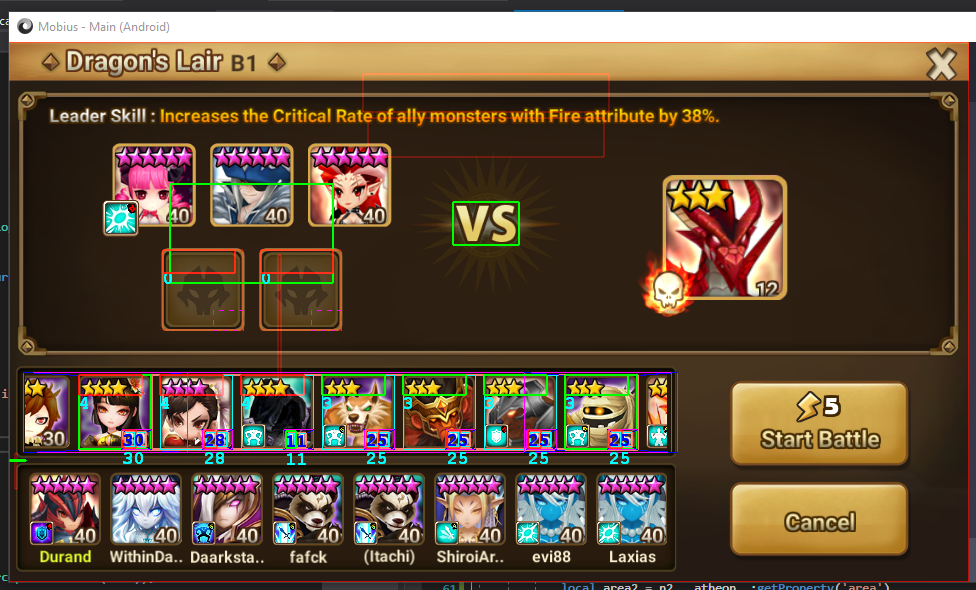
After identifying the icons, the pipeline runs OCR on the bottom right and a classifier on the top left of each icon. Now let's look at another modularity example.
With Our Powers Combined
I recently found myself training a model to distinguish ~1000 different items in an MMORPG. It is pretty accurate, but it would occasionally misclassify. Because the script was sometimes using the model to identify items in specific equipment slots, I realized I could weigh the output based on the expected items. When the ConvNet runs against the amulet slot, for example, the output vectors would be weighted towards classes which correspond to amulets.
This worked well, and the addition of a Cognition capable of multiplying vectors– which literally took a minute to implement–enabled something much more powerful: ensemble models. With a few minutes of changes to the Lua code, the engine was running multiple ConvNets, combining their output, and weighing it towards the expected classes. Here's what that looks like classifying my favorite weapon:

The first two sets of vectors are outputs from two different ConvNets. To the right is the output of their multiplication (black/blue) and the weights for the weapon slot (white/purple). In this case, the weights are 1.0 for any outputs corresponding to weapons and 0.5 otherwise.
This accidental mechanism works exceptionally well, as it allows me to combine models trained on generated and collected samples, creating classifications that are much more resilient than with either model alone.
Before moving on, let me clarify the pipeline. Keep in mind that Spread takes a Perception on the left, runs it against multiple pipelines, and returns a multi-perception:
Crop -> Vectorize -> Spread(
ConvNet, // Trained on collected data
ConvNet // Trained on generated data
) -> MultiplyVectors -> Spread(
{}, // Empty, gives result of MultiplyVectors (left is passed along)
VectorWeights // Loaded from a JSON file (left is irrelevant)
) -> MultiplyVectors -> ClassifyVectors -> LabelClassIn addition to this pipeline, whose job is to turn images of items into strings with their name, there is another whose job is to turn images of items into true or false, depending on if an item is present. In this case, class 0 means there is no item present. Here is the pipeline:
Crop -> Vectorize -> Spread(
ConvNet,
ConvNet
) -> MultiplyVectors -> Spread(
{},
WeightVectors
) -> MultiplyVectors -> ClassifyVectors -> MatchClass // Look hereYou'll notice that the only difference is the final Cognition in the outer-most pipeline: MatchClass replaced LabelClass. This brings us to my final point on this topic: in Figure 3, the results of both MatchClass and LabelClass originate from the same branch. In the Lua code, they are in fact two different pipelines used in two different places. Because of the Cognition factory and PerceptionCache, though, the work for all but one operation is shared and deduplicated.
Modular == Testable
This modularity really shines in testing. The legacy vision engine was quite hard to write tests for, which meant I had very few tests. Creating a unit test meant marking up the entirety of a frame and comparing the markup to some convoluted output. In Atheon, each Cognition has a set of dedicated unit tests. Writing these tests is much easier, and they can express and test the full range of states.
Summary
The Atheon vision engine, born from the lessons of a lesser engine, is extremely fast and capable. When it replaced the legacy engine, RAM usage of scripts dropped ~10x, frame processing time dropped by ~25x, and development became a lot easier.
It owes this performance to a lightweight, caching-first design which is tailor-made for the specific niche of computer vision for graphical user interfaces. It is the heart of a much larger platform, built to provide generic, modular, and extendable automation software.
In future posts, I'll talk about all of the parts of the system. But, for now, I hope you enjoyed this look at my vision engine. As a parting gift, here is a clip of the bot in action. It is using an overlay to render information about the perception tree for each frame while following some user-defined rules at 20 frames per second.